本功能利用Python语言基于Selenium,xlwt库实现
在静态网页爬虫的博客中已经提到,对于Bilibili这样当下绝大多数的网站,页面的内容不是通过源代码一次性呈现的,多数网页的数据是异步传输并通过js根据用户动作实时渲染的,这就给我们爬取页面数据造成了很大的困难,我们无法在urllib拉取的页面源代码中找到我们想要的东西,这时我们便需要通过Selenium库对网页内容进行实时抓取。
Selenium库相比于urllib+BeautifulSoup+re的优缺点十分明显,Selenium操作简便,抓取方式多样,可以抓取动态网页,但对比后者抓取速度较慢,能耗开销较大,不够稳定,很容易受网络连接质量等因素影响,很难封装成可执行程序,而且不宜隐藏脚本属性。但瑕不掩瑜,之后再编写爬虫,我依旧会首先考虑Selenium。
Selenium的实操
首先安装Selenium并下载对应浏览器内核并将其添加进系统路径中…此处省略五百字
首先利用webdriver打开需要抓取数据的网站。我利用的是Chrome有头浏览器,以下便以Chrome为例,由于无头浏览器对于数据的定位比较难,而且有头浏览器可以监视数据的事实抓取状态,所以我还是选择了有头浏览器(我菜)。
browser=webdriver.Chrome()
browser.get(url)
之后就可以着手进行数据的定位以及抓取了,对于数据的方式,我推荐使用Xpath方式,可以快速定位到抓取信息的位置,而且有十分方便的Chrome插件(Xpath helper)可以提供实时响应。
利用Xpath路径进行定位。
首先对Xpath语法进行基础的了解。

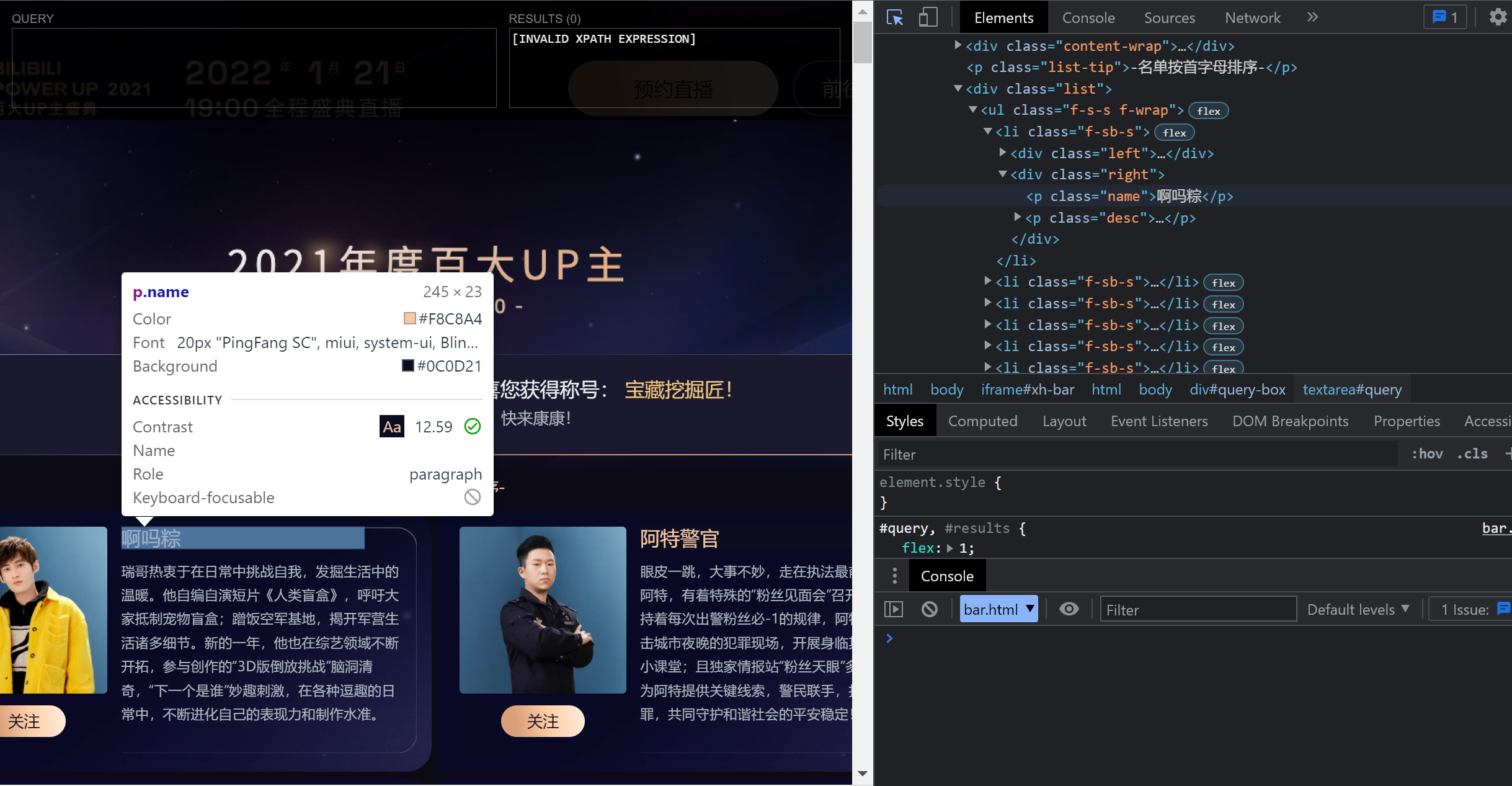
我们以Bilibili百大Up主页面为例,我们需要获得每个Up主的昵称,简介以及头像图片。
首先利用控制台的光标定位到我们需要的信息(此处以昵称为例):
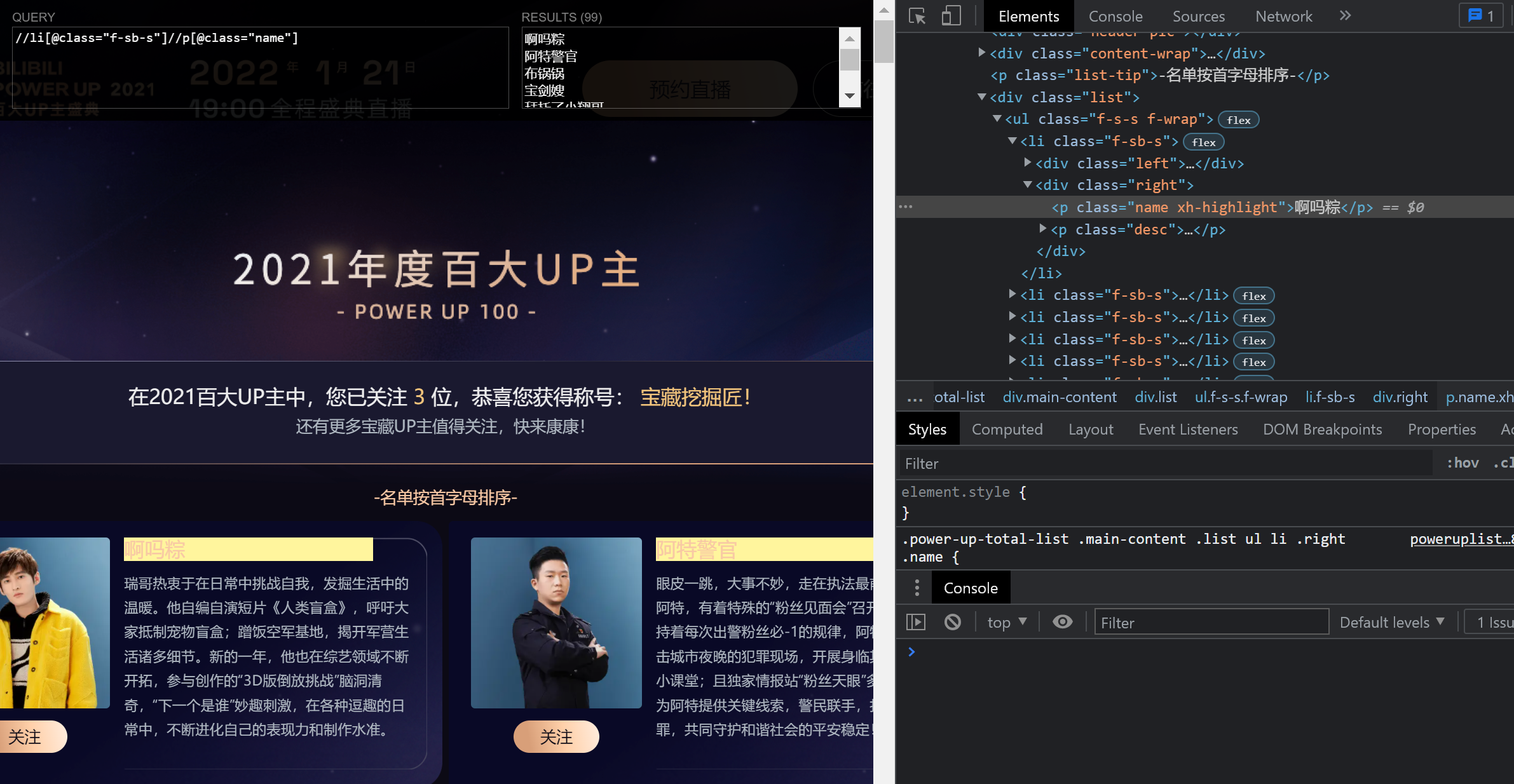
然后按照Xpath语法规范定位到相应的代码块
//li[@class="f-sb-s"]//p[@class="name"]
之后就可以利用find_element命令对于对应信息进行提取了。需要注意,在当前版本Selenium中find_element_by_xpath已被弃用。我们应引入from selenium.webdriver.common.by import By,利用browser.find_elements(By.XPATH,url)进行信息的提取。
desc=browser.find_elements(By.XPATH,'//li[@class="f-sb-s"]//p[@class="desc"]')
name=browser.find_elements(By.XPATH,'//li[@class="f-sb-s"]//p[@class="name"]')
profile=browser.find_elements(By.XPATH,'//li[@class="f-sb-s"]//div[@class="cover"]')
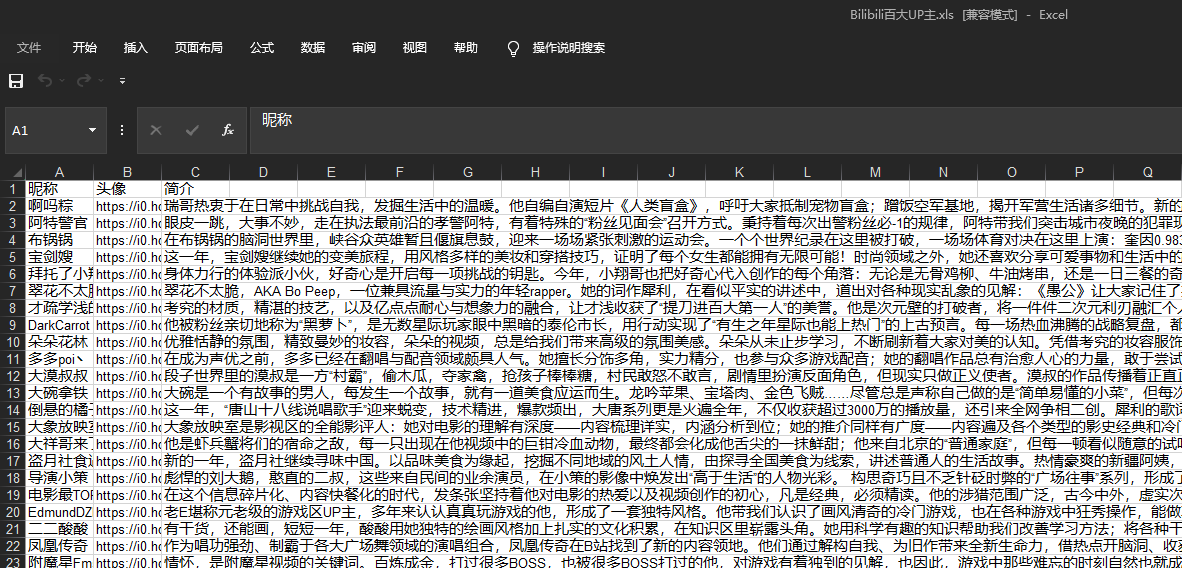
至此我们已经完成了主要信息的抽取,接下来就剩下了信息的保存。
首先将爬取的数据对应着存在一个列表中。
for i in range(0,99):
# tmp=item.get_attribute("style")
data=[]
print(name[i].text)
print(desc[i].text)
print(profile[i].get_attribute("style")[23:141])
data.append(name[i].text)
data.append(profile[i].get_attribute("style")[23:141])
data.append(desc[i].text)
datalist.append(data)
再利用和静态爬虫相同的方式存在excel表中。
def savedata():
savepath="Bilibili百大UP主.xls"
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = book.add_sheet('Bilibili百大UP主', cell_overwrite_ok=True)
col = ("昵称","头像","简介")
for i in range(0,3):
sheet.write(0,i,col[i])
i=0
for item in datalist:
data = item
for j in range(0,3):
sheet.write(i+1,j,data[j])
i=i+1
book.save(savepath)
大功告成!
©著作权归作者所有

