本功能利用Python语言,基于BeautifulSoup,re,urilib,xlwt库实现。
某些页面需要借助gzip,io等库进行处理,才能正常拉取网页源码。
谈起Python学习,爬虫的编写是一个很不错的入门选择,流程较短且成效较快。今天就介绍记录一下如何利用Python进行静态网页的爬取。写这个不是为了教会你,只是为了记录一下这两天的coding,免得忘记了,我自己都没完全搞明白,何谈教你😂。
写爬虫本来是想爬取一下今年的Bilibili百大Up主的信息,写完才发现仅仅基于静态爬取根本无法实现😭
后续我也会补一篇如何进行动态网页爬取的博客,记录一下我是如何爬取Bilibili百大Up主的信息的。
闲话少谈,进入正题。
urllib库的作用
urllib库的作用主要是拉取网页源码,获取网页原始数据,在爬虫中主要使用的命令是urllib.request中的openurl以及Request,至于urllib.error,仅仅是对网页异常状态进行判断,作用不大,仅作了解。
urllib.request.urlopen(request):按照request封装的请求打开网页,获取网页源码,request可以仅仅是一个url,也可以是封装了许多信息的一个请求,对于一些较为开放的网站比如百度等我们可以直接利用裸url进行拉取,而对于豆瓣一类稍作反爬的网站,则需要在request请求中封装headers,比如user-agent等进行访问,否则会报418。你就是个杯具
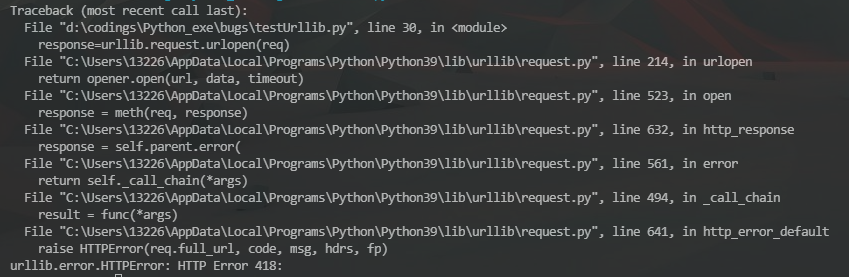
注意利用urllib.request.urlopen(request)时,若想以人类可以理解的语言查看,还需对其利用UTF-8解码模式进行解码,即.read().decode('UTF-8'),这样即可获得人类可以分析的网页源码。
小插曲:不知是不是VSCode的终端有位数限制,我总是无法在终端中print出所有源码,针对这种情况,我直接利用文件读写操作将获得的源码写入test文件中,解决了这个问题,为此我还去重新学了一下Python的文件读写操作🤣。How poor my Python is.
在这一步操作中还可能出现无法解码等错误,可能会出现此类报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
这是网页对数据进行了压缩处理,我们无法直接利用utf-8进行解码,需要先对数据进行解压缩之后再进行解码操作:
req=urllib.request.Request(url="https://www.bilibili.com/BPU2021#/poweruplist",headers=H )
response=urllib.request.urlopen(req)
htmls = response.read()
buff = BytesIO(htmls)
res= gzip.GzipFile(fileobj=buff)
text=res.read().decode('UTF-8')
urllib.request.Request():用来封装访问请求,参数中可以包含url,headers,主要在headers中对程序进行伪装,可以通过浏览器的log读取用户在当前浏览器的画像,如cookie,user-agent等,按照这些参数对我们的程序进行伪装。
H={
"cookie":"buvid3=1F5EE0AB-0149-8DC6-9C89-953157CE068260962infoc; _uuid=968BBAAC-39F4-26106-19CE-7ED2432C10FB1062353infoc; buvid_fp=1F5EE0AB-0149-8DC6-9C89-953157CE068260962infoc; CURRENT_FNVAL=2000; blackside_state=1; rpdid=|(JukYmJul~0J'uYRuR~JRRJ; sid=bmzaj1dm; innersign=0; fingerprint=5b5c948ff52bc6becc5f720b86468b1d; buvid_fp_plain=undefined; b_lsid=F2CF1A10F_17E6BAD066C; PVID=6; i-wanna-go-back=1; b_ut=8",
"accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding":"gzip, deflate, br",
"accept-language":"en-US,en;q=0.9",
"cache-control":"max-age=0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "document",
"sec-ch-ua": '" Not;A Brand";v="99", "Google Chrome";v="97", "Chromium";v="97"',
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
}
urllib还有好多很有趣很实用的命令比如getheaders等,但是对于这个功能没什么作用,故不作记录了,随用随查吧。其实是写了也记不下来(
BeautifulSoup库的作用
BeautifulSoup是对于urllib库功能的一个延申,要在urllib操作的基础上进行。 在利用urllib拉取了网页源码后, 便可以利用BeautifulSoup对数据进行检索和筛选,可以根据tag中的属性等对源码进行分析,也可以进行树形结构遍历,但是对于爬取网页特征内容,还需进行正则搜索,我们仅需创建BeautifulSoup对象,按照tag特征属性定位所需信息所处的位置,剩下的,就交给正则搜索。
html = askURL(url) # 保存获取到的网页源码
soup = BeautifulSoup(html, "html.parser") #创建BeautifulSoup
for item in soup.find_all('div', class_="item"): # 查找所所有符合要求的tag,之后利用正则搜索在其中筛选出我们需要的信息
... ...
正则搜索
没别哒,考验找规律能力的时候到了。善用浏览器控制台的光标按钮。有助于更快的定位。给几个例子,再给张参考表,随用随查吧,挺简单的东西。这不是和office一样吗?
给个正则表达的参考
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,输出括号里的数据。
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) #re.S的作用:忽略换行符,防止因为.不包括换行符,防止在字符串中出现换行符造成错误的情况。
findTitle = re.compile(r'<span class="title">(.*)</span>') #r的作用:防止生成转义字符
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
然后就可以利用findall在已创建好的BeautifulSoup对象中进行筛选了。
for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串
data = [] # 保存一部电影所有信息
item = str(item)
link = re.findall(findLink, item)[0] # 通过正则表达式查找
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") #消除转义字符
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
EZ!
xlwt库的作用
保存到excel表中,一看就懂,看注释吧,这东西也没啥花样。
def saveData(savepath):
savepath="test.xls"
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('sheet_test', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分")
for i in range(0,5):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
加一个main函数,异步进行数据拉取(urllib),数据处理(BeautifulSoup,正则提取),数据保存(xlwt),即可得到一张爬取到的数据的excel表。
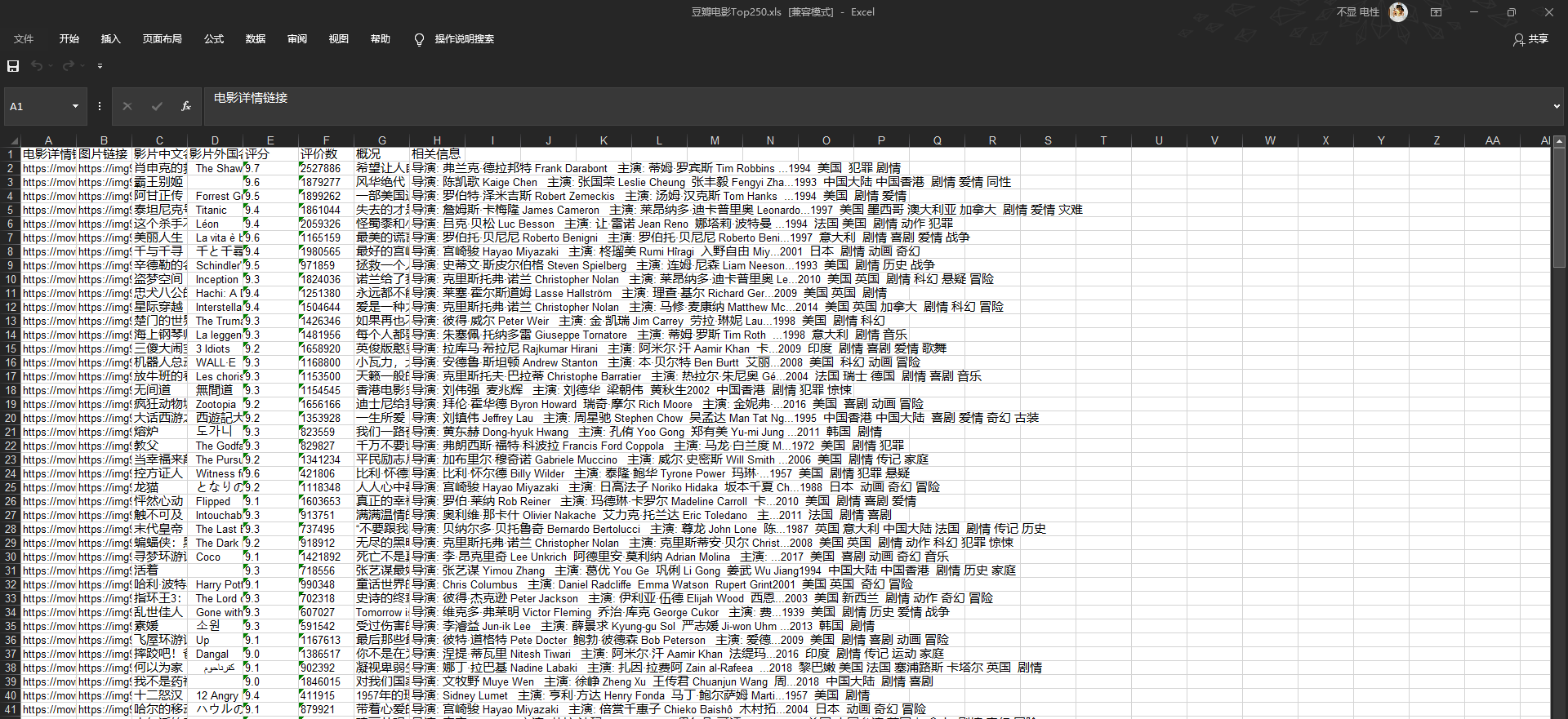
学到这我兴冲冲地打开了Bilibili,准备爬百大Up,不管我怎么修改我的代码,我爬取到的网页源代码总是和我在控制台中看到的element不同。
寄,Bilibili的数据是异步加载的。tnnd,和我玩阴的是吧。这篇博客的内容仅使用于静态网页,即不通过js动态加载元素的,右键查看源代码与控制台元素相同的网页。关于动态网页的爬取,留到下一篇博客吧。
©著作权归作者所有


