好久不见,暑假来了,我又回来了
Update 几篇前些日子看的论文笔记,连着考试两个月实在难顶。
SANER
半监督模型
数据集样式
未加标注的文本文件
模型整体框架
核心思想:提出语义扩充的方式来增强命名实体的识别效果
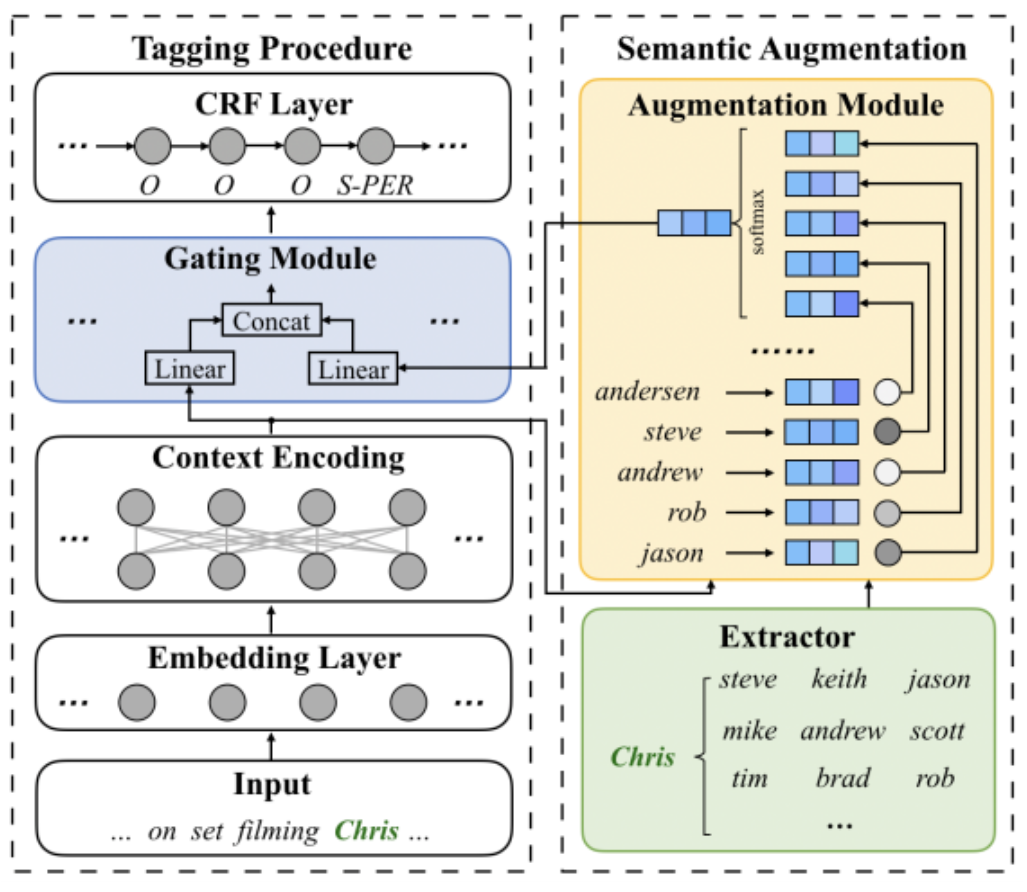
上图为paper中模型框架图,主要分两个部分,第一部分是左边子图的Tagging Procedure,第二部分是右边子图的Semantic Augmentation。前者可看着一个正常的序列标注识别框架,后者是论文提出的语义扩充的实现思路。其中,Gating Module是二者融合的模块。
模型IO
Embedding Layer
输入:不含有标记的文本文件
输出:转化后的词向量
本层中采用word2vec,GloVe等类似预训练词向量进行转化。
Context Encoding
输入:转化后的词向量
输出:包含信息的编码向量h
本层采用一种变体Transfomer结构进行文本编码,通过encoder后,输入的文本得到对应的编码向量,其中不仅包含本身信息,也包含前后文关联信息。
Augmentation Module
输入:包含信息的编码向量(h)以及预训练的向量矩阵中与h最相似的前m个词
输出:该h的语义扩充信息v
称预训练的向量矩阵中与h最相似的前m个词为该h的相似集合。但在相似词集合中,并不是每个词都是有用的,接着做一次类似attention方式计算,将每个相似的贡献区别性对待。
最后将相似集合中的所有词语经过attention计算得到的贡献权重与其本身的词向量作积,再求和,即可得到本个h的语义扩充信息v
Gating Module
输入:包含信息的编码向量h和该h的语义扩充信息v
输出:二者的融合向量
是实现向量h与v的融合,在融合的时候,文中采用控制门的形式,详见原文
CRF Layer
输入:Gating Module处理得到的融合向量
输出:不同词语的label
输出格式:
...
since O
Fragrant B-creative_work
posted O
it O
here O
, O
Daily O
Edge O
Sid B-person
a O
piece O
...
利用普通CRF计算
Reference
论文名称:
Named Entity Recognition for Social Media Texts with Semantic Augmentation
Locate & Label
半监督模型
数据集的样式
不含有任何标注的文本文件
模型整体框架
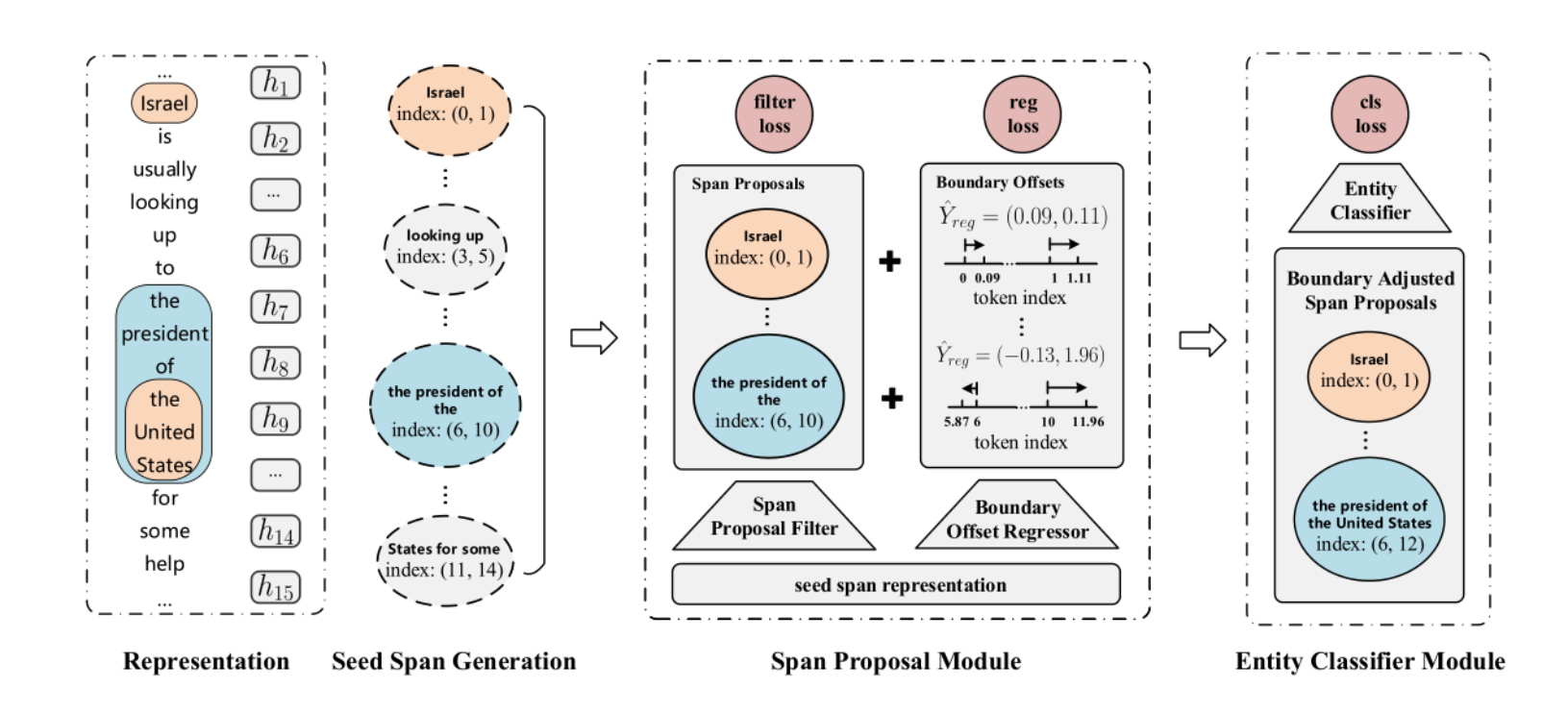
表示阶段:
利用特定方法来生成词语表示(word representation )和种子跨度(seed span),具体生成方式将在模型IO中介绍
第一阶段:
有一个span建议模块,该模块包含两个组件:过滤器和回归器。
过滤器将种子跨度分为上下文跨度和跨度建议,使用IoU,在这些种子跨度中,而重叠程度较低的部分为上下文跨度(contextual spans),实体重叠程度较高的部分为提案跨度(proposal spans)。并过滤掉前者以减少候选跨度。回归器通过调整跨度建议的边界来定位实体,以提高候选跨度的质量。
第二阶段:
使用实体分类器来标记实体类别,以减少数量并提高质量。在训练期间,为了更好地利用部分与实体匹配的跨度,我们通过基于IoU对模型的损失进行加权来构造软示例。此外,还可将软非最大抑制(soft NMS)(Bodla et al.,2017)算法应用于实体解码,以消除误报。
模型IO
Token representation:
输入:原始数据集
输出:词语表示(word representation)向量
一个句子有n个单词,对于第i个单词,我们通过链接他的word embedding,上下文字符,词性标注pos,以及字符级嵌入char
word embedding 由具有相同设置的BiLSTM模块生成;对于上下文字符,我们遵循2020年的文章获取目标标记的上下文相关嵌入,每边有一个环绕的句子。最后concat后放入BiLSTM来获得隐藏状态获得最终的word representation
Seed Span Generation
输入: 原始数据集
输出:带有分配类别(corresponding category)和回归目标(regression target)的种子跨度
- 获取种子跨度集
依照一个长度限制L,枚举获取所有可能的种子跨度区间,B代表生成的种子跨度集,
Under the constraint of a prespecified set of lengths, where the maximum does not exceed L, we enumerate all possible start and end positions to generate the seed spans. We denote the set of seed spans as B = {b0, . . . , bK}, where bi = (sti , edi) denotes i-th seed span
- 获取跨度分配类别和回归目标
我们将B中的每个种子跨度与跨度具有最大IoU的ground truth实体配对,进行交并计算后便可得到。我们根据两个之间IoU将他们分为了正跨度和负跨度;正跨度是和gt是同一标签,负跨度则是None标签。正负跨度比例为1:5。
For training the filter and the regressor, we need to assign a corresponding category and regression target to each seed span.
Span Proposal Module
输入:词语表示(word representation)向量和种子跨度(seed span)
输出:调整后的种子跨度(seed span)
这个模块是为了将种子跨度调整到一个更加精确的范围(一个可以更加精确地囊括实体的范围),其将跨度分为了跨度建议(质量高)和上下文跨度(质量低),目的是消除后者,降低成本。
Span Propos Module由两部分组成: Span建议过滤器和边界回归器; 前者用于删除上下文范围并保留范围建议,而后者用于调整范围建议的边界以定位实体。
利用了池化,概率和回归的相关技术。
Entity Classifier Module
输入:调整后的种子跨度(seed span)
输出:实体的类别
过程过于冗长,在此不加赘述
Reference
论文标题: Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition
FGN
淦,markdown源码叫我弄丢了,但是当初保存的PDF还在,放在这里以作纪念。RIP
FGN-NER
©著作权归作者所有