Attention is all U need
在了解transformer模型之前,我们首先要搞清self-attention的概念。
Self-attention,输入是一串vector set,输出亦然,RNN网络同样可以实现类似的事情而且更好搭建,但是Self-attention可以实现数据的并行处理,而RNN仅可以实现串行,所以优先研究这个效率较高的方向了,也可能会去学一下RNN,因为这个搭建起来实在是太麻烦了,放在Pytorch便签中吧。
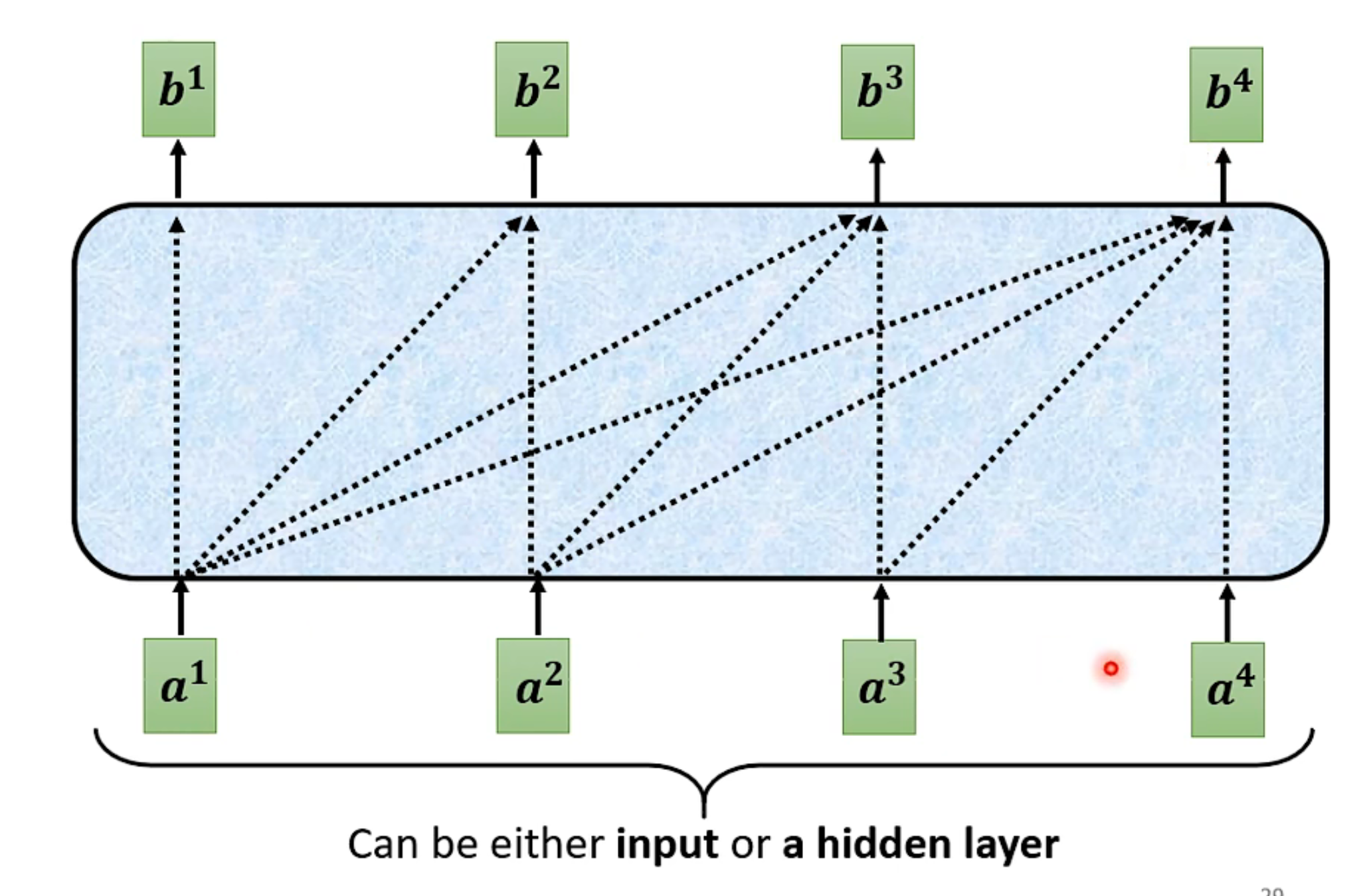
Self-attention其实不难理解,简而言之就是用各种方法在输入的向量间找彼此的关系α,然后对输入内容进行预测,输出一个vector set。直接上图。
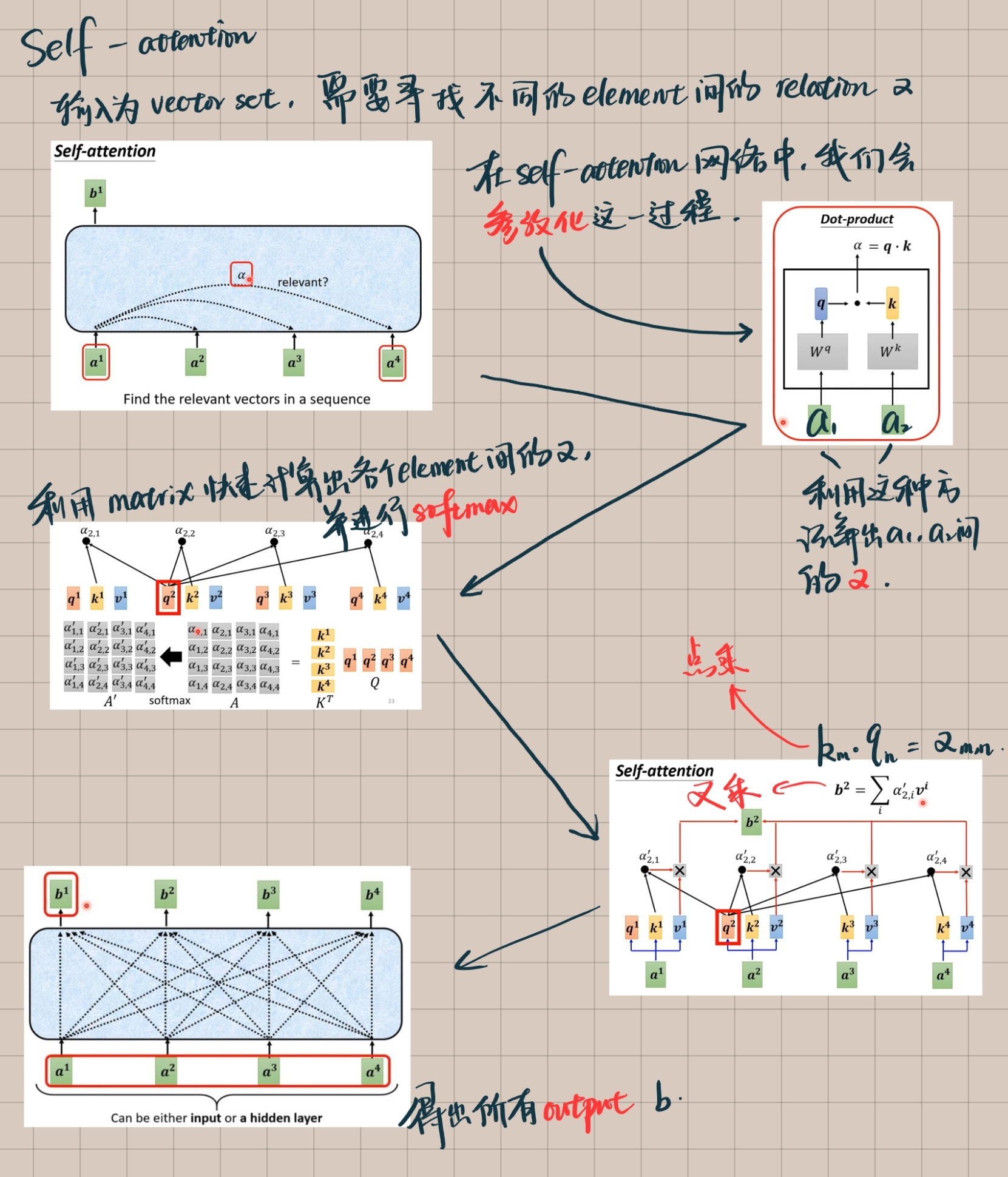 这是self-attention的整个流程,并非神经网络!若要进行机器学习训练,还需要搭建神经网络,这也便有了transformer模型。
这是self-attention的整个流程,并非神经网络!若要进行机器学习训练,还需要搭建神经网络,这也便有了transformer模型。
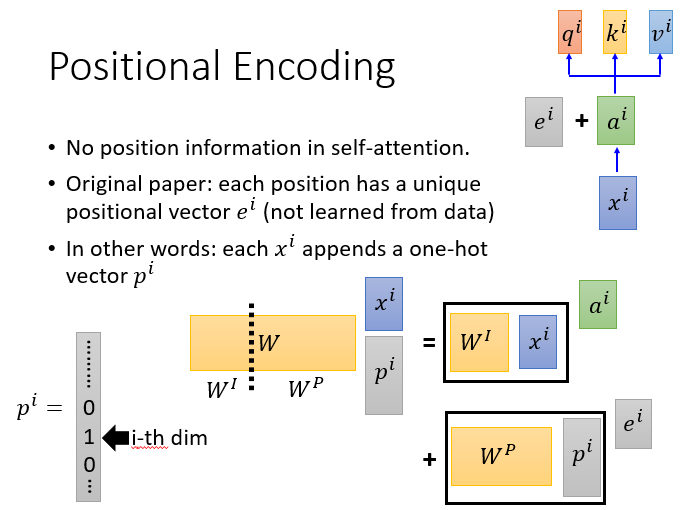
在原始论文中Self-Attention中没有考虑位置信息,不妨加一个ei来表示位置信息,怎么理解呢,可以理解为在xi向量上加了一个one-hot表示的pi,然后经过计算发现ei并不影响原来的向量,所以加入这个位置信息不仅不会影响已有的数据,还能在输入中加入有关位置的信息,可谓一举两得。
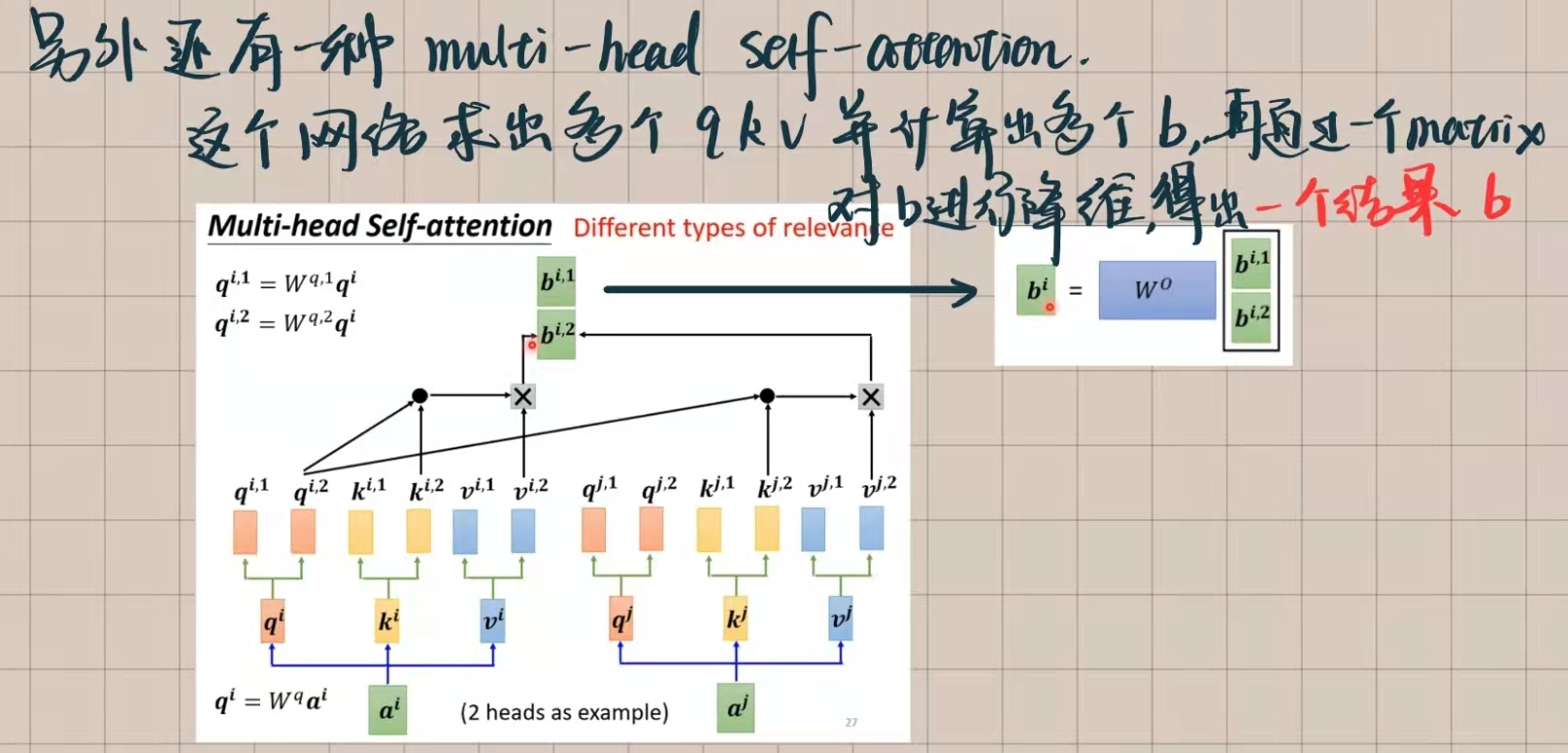
其实,transformer模型和上述过程并非完全相关,与之更为相关的是下方的multihead
 看过了整个路程,不难发现我们需要学习的参数一共就下面几个儿
看过了整个路程,不难发现我们需要学习的参数一共就下面几个儿
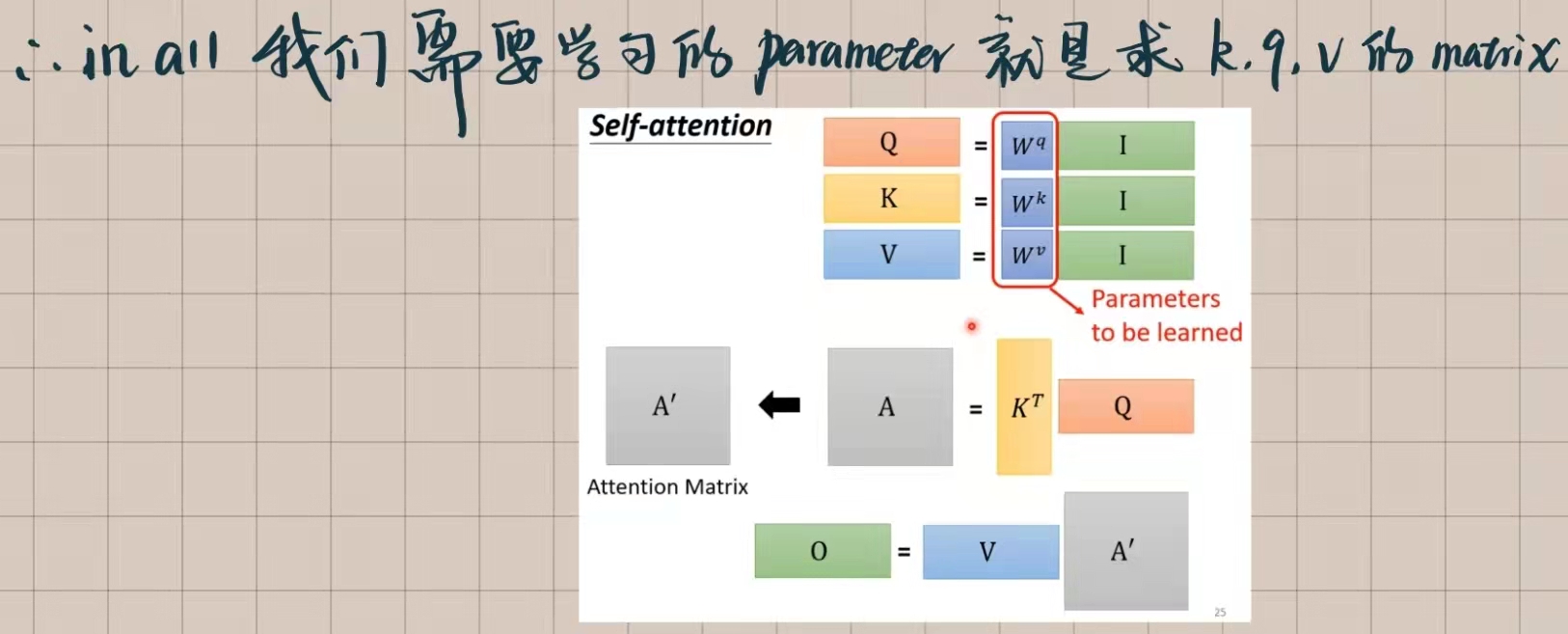 Self-attention也就这么多,下面进入正题transformer。
Self-attention也就这么多,下面进入正题transformer。
Transformer实现
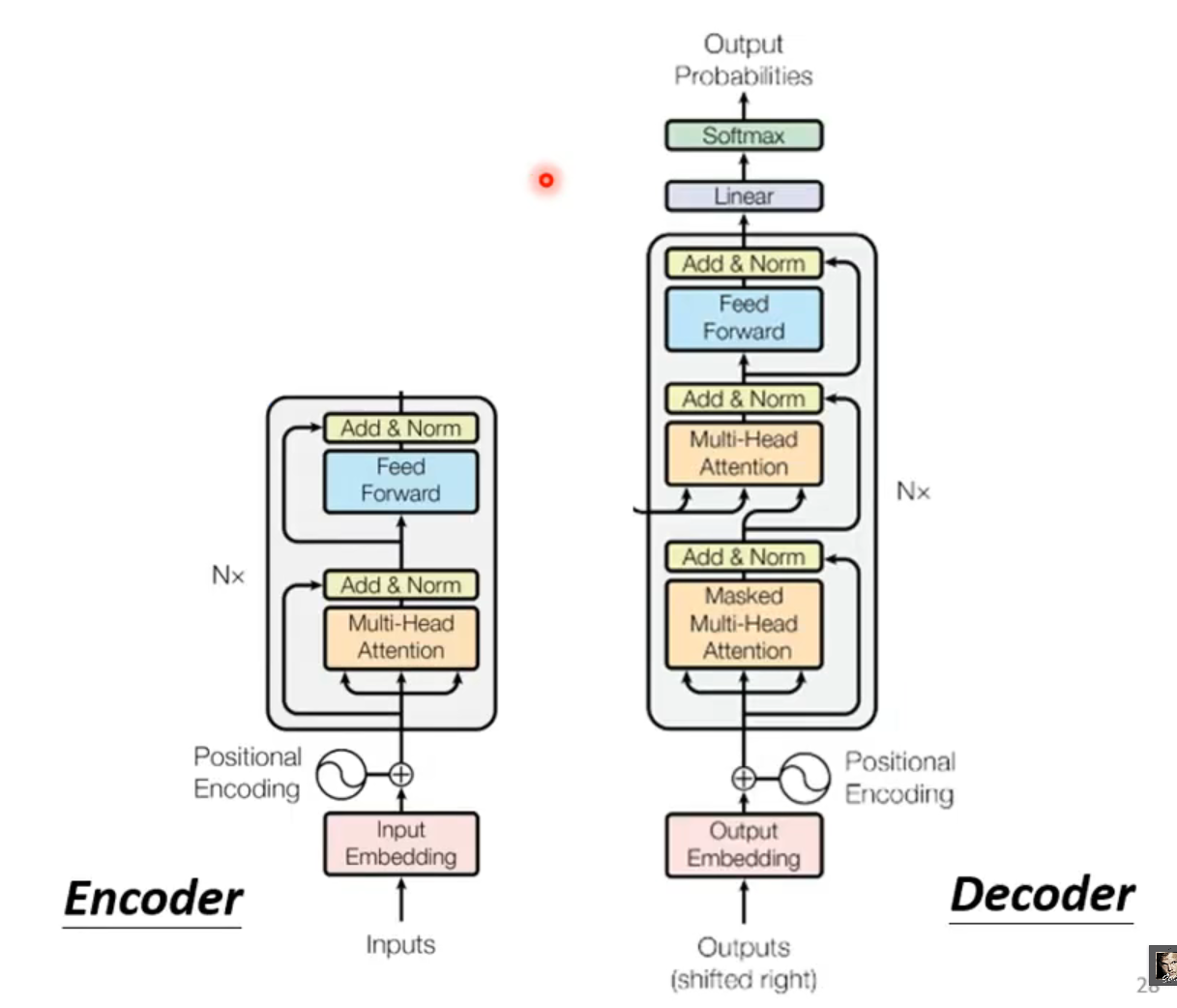
这个模型可以看成是一个黑箱操作。在机器翻译中,就是输入一种语言,输出另一种语言。
 这个黑箱是由编码组件、解码组件和它们之间的连接组成。
这个黑箱是由编码组件、解码组件和它们之间的连接组成。
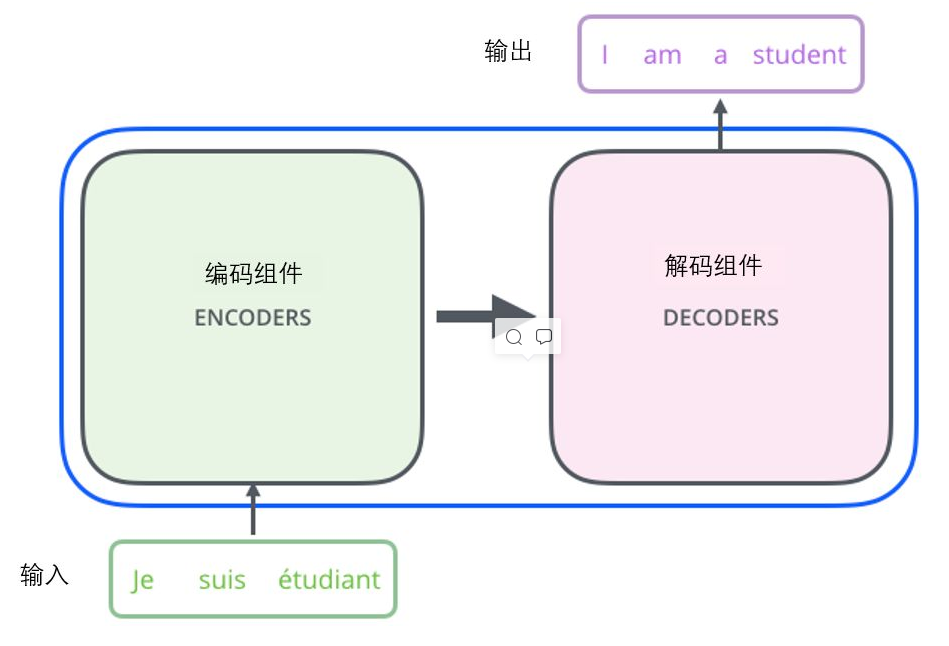
编码组件部分由一堆编码器(encoder)构成(论文中是将6个编码器叠在一起)。解码组件部分也是由相同数量(与编码器对应)的解码器(decoder)组成的。所有的编码器在结构上都是相同的,但它们没有共享参数。每个解码器都可以分解成两个子层。
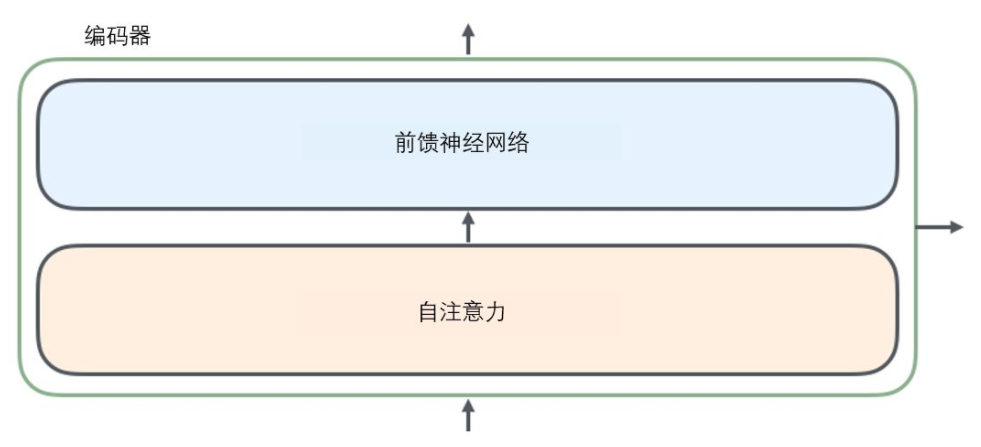
从编码器输入的句子首先会经过一个上文提到的自注意力(self-attention)层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。
自注意力层的输出会传递到前馈(feed-forward)神经网络中。每个位置的单词对应的前馈神经网络都完全一样。
解码器中也有编码器的自注意力(self-attention)层和前馈(feed-forward)层。除此之外,这两个层之间还有一个注意力层,用来关注输入句子的相关部分(和seq2seq模型的注意力作用相似)。
Transformer 的 Decoder的输入与Encoder的输出处理方法步骤是一样地,一个接受source数据,一个接受target数据,举个例子:Encoder接受英文”Tom chase Jerry”,Decoder接受中文”汤姆追逐杰瑞”。只是在有target数据时也就是在进行有监督训练时才会接受Outputs Embedding,进行预测时则不会接收。
之后就要引入我们的张量了,我们首先将每个输入单词通过词嵌入算法转换为词向量,每个单词都被嵌入为512维的向量。
词嵌入过程只发生在最底层的编码器中。所有的编码器都有一个相同的特点,即它们接收一个向量列表,列表中的每个向量大小为512维。在底层(最开始)编码器中它就是词向量,但是在其他编码器中,它就是下一层编码器的输出(也是一个向量列表)。向量列表大小是我们可以设置的超参数——一般是我们训练集中最长句子的长度。
我们还需要给每个word的词向量添加位置编码positional encoding,为什么需要添加位置编码呢?
首先咱们知道,一句话中同一个词,如果词语出现位置不同,意思可能发生翻天覆地的变化,就比如:我欠他100W 和 他欠我100W。这两句话的意思一个地狱一个天堂。可见获取词语出现在句子中的位置信息是一件很重要的事情。
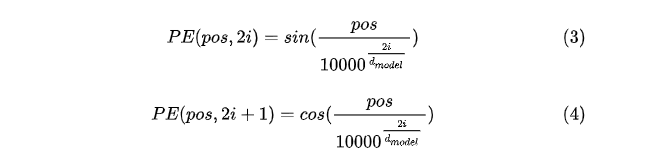
这positional encoding的获取也是一门学问,一般我们会用下面两个公式来获取。
啥?你问为啥?别问,问就是古圣先贤。
encoder
self-attention结构如下图所示:

但在encoder layer中运用的架构并非这一个,而是Multi-Head Attention,这个问题在上文也有讨论过,其实它就是在self-attention的基础上,对于输入的embedding矩阵有多个矩阵进行数据的处理,并在得到多个结果后再进行降维,得到最终结果。
而这个降维操作,展开来说就是Add&Normalize
简单来说,Add操作的作用就是在输入中加入残差块,防止神经网络由于layer过多在训练过程中产生退化问题,而这个残差块涉及到resnet方面的知识,我们目前可以将其理解为将output和input进行求和后输出。
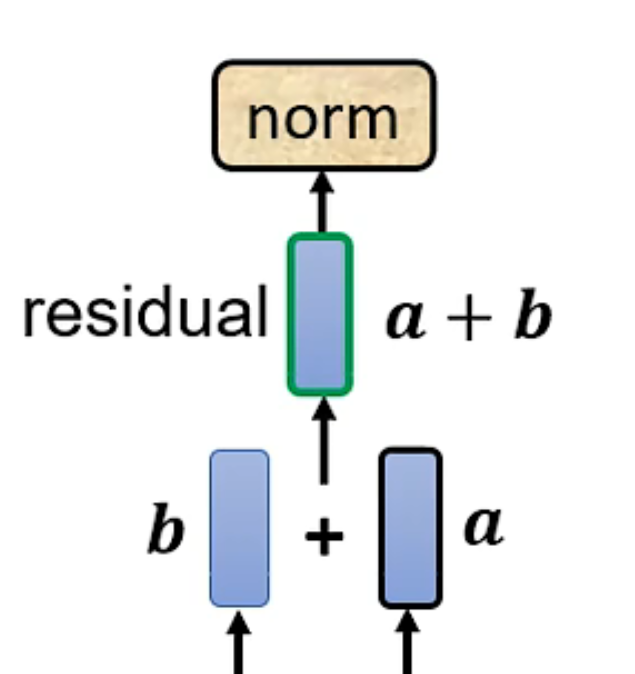
Normalization则是在之前很常见的归一化数据的手段,能够加快训练的速度,提高训练的稳定性,也能让训练数据看起来更加规则。
但在transformer中,进行Normalization的手段并非之前提到的Batch Normalization,而是一种新的Normalization方式,称为Layer Normalization。二者的差别如下图所示
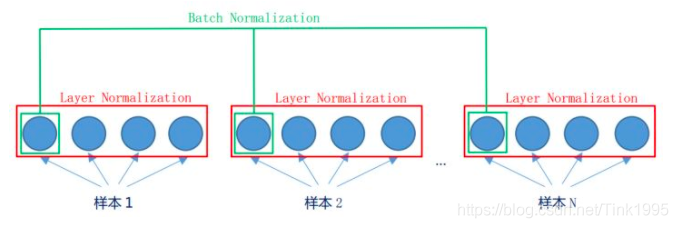
Layer Normalization是在同一个样本中不同神经元之间进行归一化,而Batch Normalization是在同一个batch中不同样本之间的同一位置的神经元之间进行归一化。
Batch Normalization是对于相同的维度进行归一化,但是咱们NLP中输入的都是词向量,一个300维的词向量,单独去分析它的每一维是没有意义地,在每一维上进行归一化也是适合地,因此这里选用的是Layer Normalization。
解决了Add&Normalize的问题,我们还面临着最后一个问题,就是前馈神经网络Feed-Forward Networks的问题。
这一部分就比较熟悉了,在之前的CNN分析图片中我们曾经用过2d的conv,这次由于单词的形式为vector,换成1d就好了,换汤不换药。这一部分的分析放到之后的代码解析部分吧。
到这里对encoder layer的分析就差不多结束了,至于encoder,就是数个encoder layer首尾相连,无他。
其实decoder的结构与encoder的结构类似,唯一多出来的一部分就是其中包含mask操作,并且decoder会吸收encoder产生的vector set。
mask操作简而言之就是对数据进行某种意义上的覆盖,不要让模型接触到多余或是错误地信息,对训练过程造成影响。
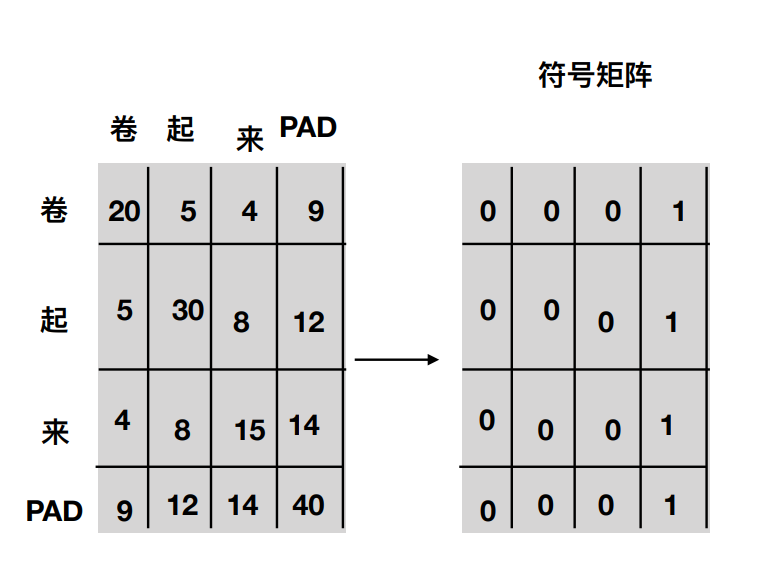
mask分为两部分,第一部分是针对padding部分的mask,由于输入的句子的长度的不统一性,我们需要padding来进行补全,使整个句子训练集可以组成一个矩阵,但在后续训练过程中,神经网络并不知道哪一部分是真实的数据,哪一部分是补的padding,为了防止padding上的数据对神经网络的训练造成影响,所以对其进行mask操作覆盖。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
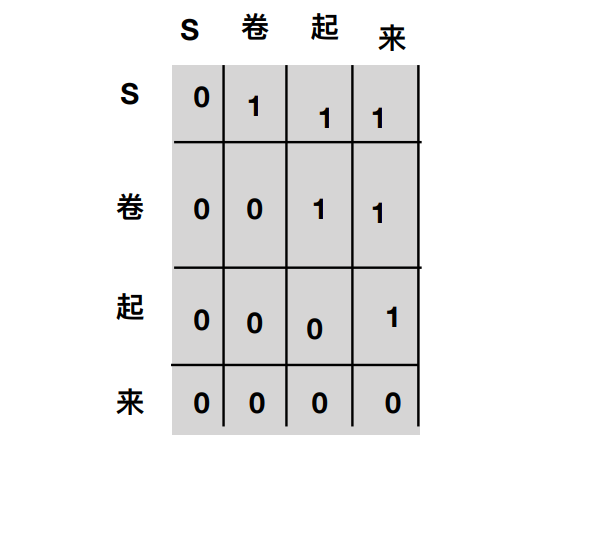
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!(在下图的例子中,矩阵为1的位置为mask要覆盖的位置)
第二部分是sequence mask,sequence mask 是为了使得 decoder 不能看见未来的信息。对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
这在训练的时候有效,因为训练的时候每次我们是将target数据完整输入进decoder中地,预测时不需要,预测的时候我们只能得到前一时刻预测出的输出。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
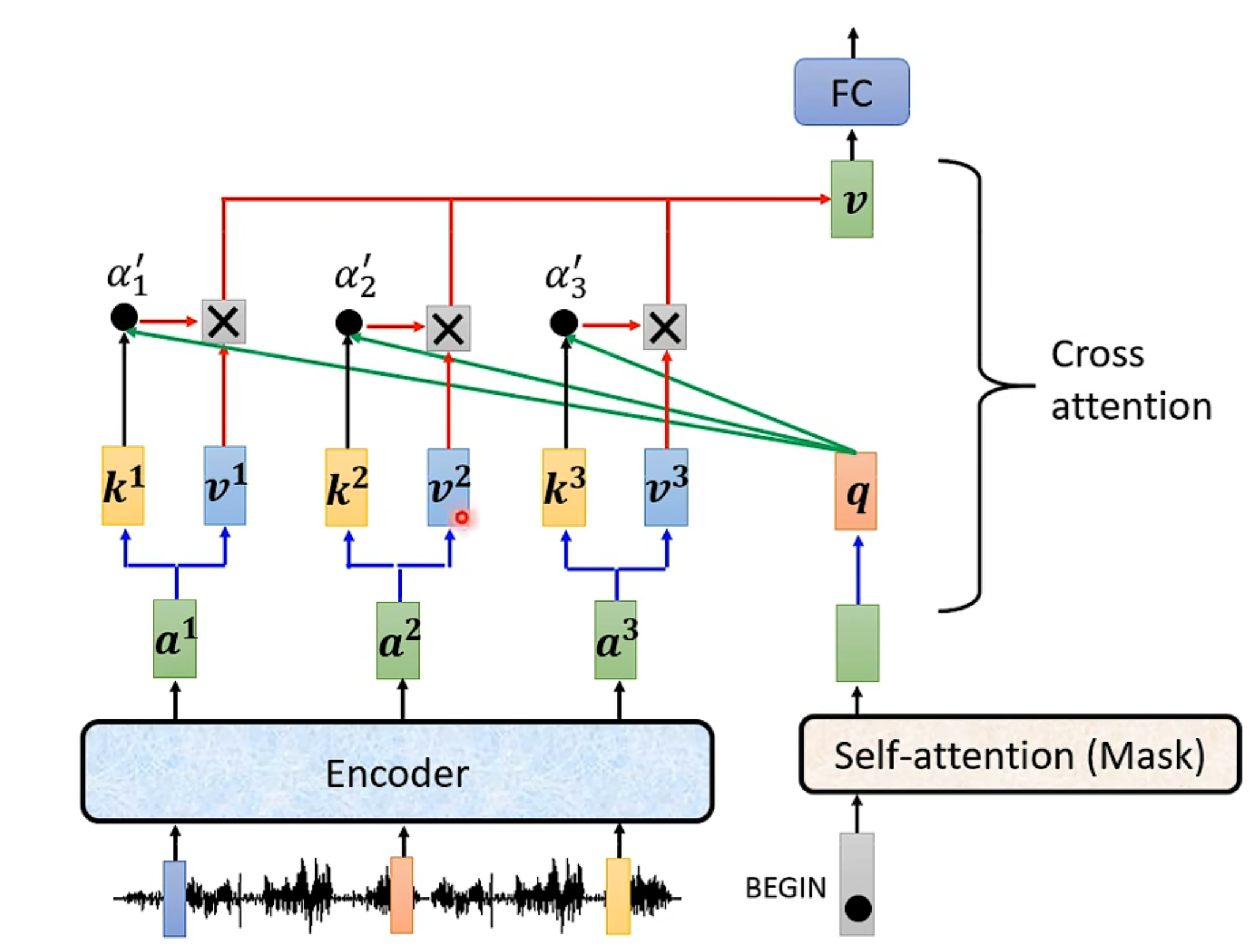
当然,我们利用encoder产生的vector set也当然要在decoder中有所运用,否则岂不是做了白工。
这一步操作称为cross attention,具体操作就是利用encoder输出的数据和decoder中输入的数据产生不同的矩阵进行两个模块数据间的求attention操作。将输出输入到fully connected layer进行拟合训练。
剩下的不同,就只剩下在decoder的输出部分了,decoder的输出部分也就是整个的transformer的输出部分。
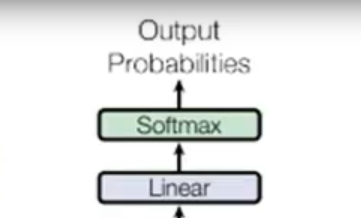
Output如图中所示,首先经过一次线性变换,然后Softmax得到输出的概率分布,然后通过词典,输出概率最大的对应的单词作为我们的预测输出。
到这里transformer的所有部分也就大概说了一遍了。下面这张图儿还挺形象的。

懂了吗?懂了,但没完全懂,下面再结合着代码看一看吧,纸上得来终觉浅,还得打开VScode。
代码解析部分
依赖的libraries如下
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import math
撅batch
def make_batch(sentences):
input_batch = [[src_vocab[n] for n in sentences[0].split()]]
output_batch = [[tgt_vocab[n] for n in sentences[1].split()]]
target_batch = [[tgt_vocab[n] for n in sentences[2].split()]]
return torch.LongTensor(input_batch), torch.LongTensor(output_batch), torch.LongTensor(target_batch)
# 我们输入的所有句子都要按照[input,output,target]格式进行输入
首先说main函数吧
if __name__ == '__main__':
## 句子的输入部分,可以输入多组句子,不过要按照上述格式进行输入
sentences = ['ich mochte ein bier P', 'S i want a beer', 'i want a beer E']
# Transformer Parameters
# Padding Should be Zero
## 构建词表
src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4} # 输入词表
src_vocab_size = len(src_vocab)
tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'S': 5, 'E': 6} # 输出词表
tgt_vocab_size = len(tgt_vocab)
src_len = 5 # length of source
tgt_len = 5 # length of target
## 模型参数
d_model = 512 # Embedding Size,将每一个词embed入512dim中
d_ff = 2048 # FeedForward dimension,神经网络深度
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer
n_heads = 8 # number of heads in Multi-Head Attention
model = Transformer() # 初始化
criterion = nn.CrossEntropyLoss() # regression常用loss function
optimizer = optim.Adam(model.parameters(), lr=0.001) # 无脑Adam Optimizer
enc_inputs, dec_inputs, target_batch = make_batch(sentences) # 撅batch,不过这个例子中只有一个例子,也就没batch不batch的说法了
for epoch in range(20):
optimizer.zero_grad() # 初始化gradian
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, target_batch.contiguous().view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward() # 回溯
optimizer.step() # 步进
这不过只是一个空架子,不,连空架子都段不上,先看一下transformer架构吧
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder() ## 编码层
self.decoder = Decoder() ## 解码层
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False) ## 输出层 d_model 是我们解码层每个token输出的维度大小,之后会做一个 tgt_vocab_size 大小的softmax,根据概率大小选择单词
def forward(self, enc_inputs, dec_inputs):
## 这里有两个数据进行输入,一个是enc_inputs 形状为[batch_size, src_len],主要是作为编码段的输入,一个dec_inputs,形状为[batch_size, tgt_len],主要是作为解码端的输入
## enc_inputs作为输入 形状为[batch_size, src_len],输出由自己的函数内部指定,想要什么指定输出什么,可以是全部tokens的输出,可以是特定每一层的输出;也可以是中间某些参数的输出;
## enc_outputs就是主要的输出,enc_self_attns是QK转置相乘之后softmax之后的矩阵值,代表每个单词和其他单词相关性;
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
## dec_outputs 是decoder主要输出,用于后续的linear映射; dec_self_attns类比于enc_self_attns 是查看每个单词对decoder中输入的其余单词的相关性;dec_enc_attns是decoder中每个单词对encoder中每个单词的相关性;
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
## dec_outputs做映射到词表的操作
dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
这终于能看出一点架子的样子了,那我们就按照代码的顺序接着往下品,先看encoder
# Encoder 部分包含三个部分:词向量embedding,位置编码部分,注意力层及后续的前馈神经网络
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model) ## 这个其实就是去定义生成一个矩阵,大小是 src_vocab_size * d_model
self.pos_emb = PositionalEncoding(d_model) ## 位置编码情况,这里是固定的正余弦函数
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) ## 使用ModuleList对多个encoder进行堆叠
def forward(self, enc_inputs):
## 这里我们的 enc_inputs 形状是: [batch_size x source_len]
## 下面这个代码通过src_emb,进行索引定位,enc_outputs输出形状是[batch_size, src_len, d_model]
enc_outputs = self.src_emb(enc_inputs)
## 这里就是位置编码,把两者相加放入到了这个函数里面,从这里可以去看一下位置编码函数的实现;
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1)
##get_attn_pad_mask是为了得到句子中pad的位置信息,给到模型后面,在计算自注意力和交互注意力的时候去掉pad符号的影响
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
enc_self_attns = []
for layer in self.layers:
## 依次通过n个encoder layer,把每一层的输出当作下一层的输入
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
下面我们依次来看一下上面提到的几个函数
PositionalEncoding
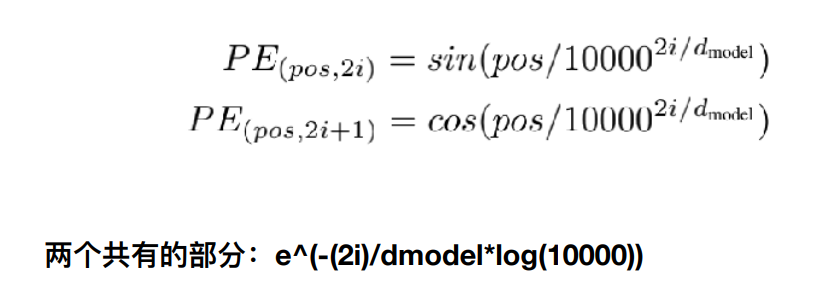
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
## 其实就是照着上面给的那个有sin,cos的公式复现
## 从理解来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)## 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,补长为2,其实代表的就是偶数位置
pe[:, 1::2] = torch.cos(position * div_term)##这里需要注意的是pe[:, 1::2]这个用法,就是从1开始到最后面,补长为2,其实代表的就是奇数位置
## 上面代码获取之后得到的pe:[max_len*d_model]
## 下面这个代码之后,我们得到的pe形状是:[max_len*1*d_model]
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe) ## 定一个缓冲区,其实简单理解为这个参数不更新就可以
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
get_attn_pad_mask
## 比如说,我现在的句子长度是5,在后面注意力机制的部分,我们在计算出来QK转置除以根号之后,softmax之前,我们得到的形状 len_input * len*input 代表每个单词对其余包含自己的单词的影响力
## 所以这里我需要有一个同等大小形状的矩阵,告诉我哪个位置是PAD部分,之后在计算计算softmax之前会把这里置为无穷大;
## 一定需要注意的是这里得到的矩阵形状是batch_size x len_q x len_k,我们是对k中的pad符号进行标识,并没有对k中的做标识,因为没必要
## seq_q 和 seq_k 不一定一致,在交互注意力,q来自解码端,k来自编码端,所以告诉模型编码这边pad符号信息就可以,解码端的pad信息在交互注意力层是没有用到的;
def get_attn_pad_mask(seq_q, seq_k):
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k, one is masking
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
EncoderLayer
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention() # 多头自注意力
self.pos_ffn = PoswiseFeedForwardNet() # 前馈神经网络
def forward(self, enc_inputs, enc_self_attn_mask):
## 下面这个就是做自注意力层,输入是enc_inputs,形状是[batch_size x seq_len_q x d_model] 需要注意的是最初始的QKV矩阵是等同于这个输入的
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # 获得彼此相关性
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]
return enc_outputs, attn
MultiHeadAttention
这也就是之前长篇大论探讨的Self-attention的主体部分
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
## 输入进来的QKV是相等的,我们会使用映射linear做一个映射得到参数矩阵Wq, Wk,Wv
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
self.linear = nn.Linear(n_heads * d_v, d_model)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, Q, K, V, attn_mask):
## 这个多头分为这几个步骤,首先映射分头,然后计算atten_scores,然后计算atten_value;
##输入进来的数据形状: Q: [batch_size x len_q x d_model], K: [batch_size x len_k x d_model], V: [batch_size x len_k x d_model]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
##下面这个就是先映射,后分头;一定要注意的是q和k分头之后维度是一致额,所以一看这里都是dk
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
## 输入进行的attn_mask形状是 batch_size x len_q x len_k,然后经过下面这个代码得到 新的attn_mask : [batch_size x n_heads x len_q x len_k],就是把pad信息重复了n个头上
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
##然后我们计算 ScaledDotProductAttention 这个函数,得到的结果有两个:context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q x len_k]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = self.linear(context)
return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]
ScaledDotProductAttention
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
## 输入进来的维度分别是 [batch_size x n_heads x len_q x d_k] K: [batch_size x n_heads x len_k x d_k] V: [batch_size x n_heads x len_k x d_v]
##首先经过matmul函数得到的scores形状是 : [batch_size x n_heads x len_q x len_k]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
## 然后关键词地方来了,下面这个就是用到了我们之前重点讲的attn_mask,把被mask的地方置为无限小,softmax之后基本就是0,对q的单词不起作用
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
PoswiseFeedForwardNet
常规操作,双层conv
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, inputs):
residual = inputs # inputs : [batch_size, len_q, d_model]
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
output = self.conv2(output).transpose(1, 2)
return self.layer_norm(output + residual)
encoder差不多就这么多,下面是decoder,和encoder类似,仅有少量补充
Decoder
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len]
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, tgt_len, d_model]
## get_attn_pad_mask 自注意力层的时候的pad 部分
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)
## get_attn_subsequent_mask 这个做的是自注意层的mask部分,就是当前单词之后看不到,使用一个上三角为1的矩阵
dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)
## 两个矩阵相加,大于0的为1,不大于0的为0,为1的在之后就会被fill到无限小
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
## 这个做的是交互注意力机制中的mask矩阵,enc的输入是k,我去看这个k里面哪些是pad符号,给到后面的模型
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
DecoderLayer
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn
get_attn_subsequent_mask
获取subsequent mask
def get_attn_subsequent_mask(seq):
"""
seq: [batch_size, tgt_len]
"""
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
# attn_shape: [batch_size, tgt_len, tgt_len]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成一个上三角矩阵
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask # [batch_size, tgt_len, tgt_len]
总算是从头到尾梳理了一遍,有些地方还是有些模棱两可,没关系,之后再研究研究,累了不想看了,收拾东西去了。
寒假过得真快,明天又开学了,不知道开学还有没有时间写博客,累啊。
唉,加油吧,坐大牢去喽,难顶😭。
©著作权归作者所有