不能再拖了
Pythorch,轮子店
Mostly Used
Numpy向Torch的转化
torch_data = torch.from_numpy(np_data)
Torch的矩阵乘法
torch.mm(tensor, tensor)
# 'mm' stands for 'matrix multiply'
# 注意此处与Numpy的区别,不能直接利用.dot()进行运算
Troch的数学运算规则几乎与Numpy一致,请参考
Torch中,若要进行反向传播,需要利用variable进行运算,variable可以一次性将所有修改幅度 (梯度) 都计算出来, 而tensor就没有这个能力。
但variable中的数据需要tensor类型导入:
tensor = torch.FloatTensor([[1,2],[3,4]])
# requires_grad是参不参与误差反向传播, 要不要计算梯度
variable = Variable(tensor, requires_grad=True)
升维
x=torch.unsqueeze(x,dim=1)
激励函数
Torch 中的激励函数有很多, 不过我们平时要用到的就这几个: relu, sigmoid, tanh, softplus。
如何利用激励函数:
# following are popular activation functions
y_relu = torch.relu(x).numpy()
y_sigmoid = torch.sigmoid(x).numpy()
y_tanh = torch.tanh(x).numpy()
y_softplus = F.softplus(x).numpy() # there's no softplus in torch
神经网络的搭建与训练
普通搭建方法:
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output): # 分别代表输入,该层神经元个数,输出
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x)) # 利用relu激励函数
x = self.predict(x)
return x
net = Net(1, 10, 1) # 搭建含有一层十个hidden神经元的神经网络
# 结构:
# Net (
# (hidden): Linear (1 -> 10)
# (predict): Linear (10 -> 1)
# )
🐶都不用,有轮子还不用?
我tm直接快速搭建
net = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(), # 注意要大写,这里的ReLU是一个class
torch.nn.Linear(10, 1)
)
# 结构:
# Sequential (
# (0): Linear (1 -> 10)
# (1): ReLU ()
# (2): Linear (10 -> 1)
# )
训练方法

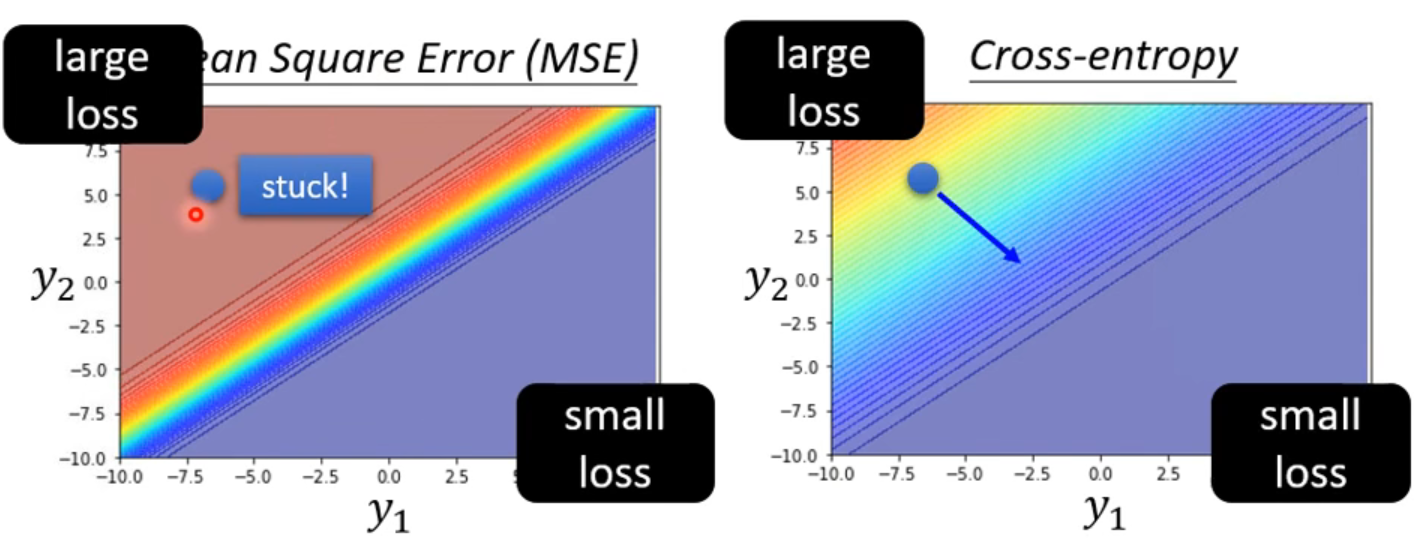
回归拟合
# optimizer 是训练的工具
optimizer = torch.optim.SGD(net.parameters(), lr=0.2) # 传入 net 的所有参数, learning rate
loss_func = torch.nn.MSELoss() # 预测值和真实值的误差计算公式 (均方差)
for t in range(100):
prediction = net(x) # 喂给 net 训练数据 x, 输出预测值
loss = loss_func(prediction, y) # 计算两者的误差,prediction要在前
optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播, 计算参数更新值
optimizer.step() # 将参数更新值施加到 net 的 parameters 上
区分类型
利用one-hot vector输出,并利用softmax进行normalization,但在Pytorch中softmax已经被整合在CrossEntropy中,故不必单独进行softmax操作

net = Net(n_feature=2, n_hidden=10, n_output=2) # 几个类别就几个 output
# optimizer 是训练的工具
optimizer = torch.optim.SGD(net.parameters(), lr=0.02) # 传入 net 的所有参数,learning rate
loss_func = torch.nn.CrossEntropyLoss()
# 注意loss function的改变,此时的输出是二维数据,比如[0.2,0.8],代表该点属于第一类别的概率为0.2,属于第二类别的概率为0.8,所以不能利用与regression相同的loss function,需要用这个
for t in range(100):
out = net(x) # 喂给 net 训练数据 x, 输出分析值
loss = loss_func(out, y) # 计算两者的误差
optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播, 计算参数更新值
optimizer.step() # 将参数更新值施加到 net 的 parameters 上
神经网络的保存与提取
save
torch.save(net1, 'net.pkl') # 保存整个网络
torch.save(net1.state_dict(), 'net_params.pkl') # 只保存网络中的参数 (速度快, 占内存少)
load
# 提取整个网络
net2 = torch.load('net.pkl') # 提取网络
prediction = net2(x) # 使用网络
# 提取网络参数
# 需要新建 net3,再将提取的参数导入该网络中
net3 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
net3.load_state_dict(torch.load('net_params.pkl')) # 将保存的参数复制到 net3
prediction = net3(x) # 使用网络
批训练
需要引入libraryimport torch.utils.data as Data实现
想要分batch,必然要利用批处理,简例如下
# 简简单单两组数据
x = torch.linspace(1, 10, 10) # x data (torch tensor)
y = torch.linspace(10, 1, 10) # y data (torch tensor)
# 先转换成 torch 能识别的 Dataset
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 把 dataset 放入 DataLoader
loader = Data.DataLoader(
dataset=torch_dataset, # torch TensorDataset format
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多线程来读数据
)
for epoch in range(3): # 训练所有数据 3 次
for step, (batch_x, batch_y) in enumerate(loader): # 每一步 loader 释放一小批数据用来学习
# training...
若all_set不是batch的整数倍也无妨,loader会在最后一次训练中将所有的数据全部放入一个batch中
Optimizer
无脑Adam就可以了
 几种常见的优化器:
几种常见的优化器:SGD, Momentum, RMSprop, Adam
使用方法:
# different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8) # 注意momentum就是SGD的套壳
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
# 首选后两个Optimizer,效果较佳
利用Pytorch搭建CNN网络
以MNIST任务为例
# 引入如下library
import torch.nn as nn
import torch.utils.data as Data
import torchvision
# 给定Hyper Parameters
EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
BATCH_SIZE = 50
LR = 0.001 # learning rate
数据的训练与测试
# 训练set的初始化
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST, # downloaded or not
)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) # 加载training set
# pick 2000 samples to speed up testing
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # 由于仅仅对train_data进行了tensor处理,同样也需要对test_data进行处理,使其取值范围在[0,1],所以对其除255
test_y = test_data.test_labels[:2000] # 仅取前2000个进行test
搭建CNN网络
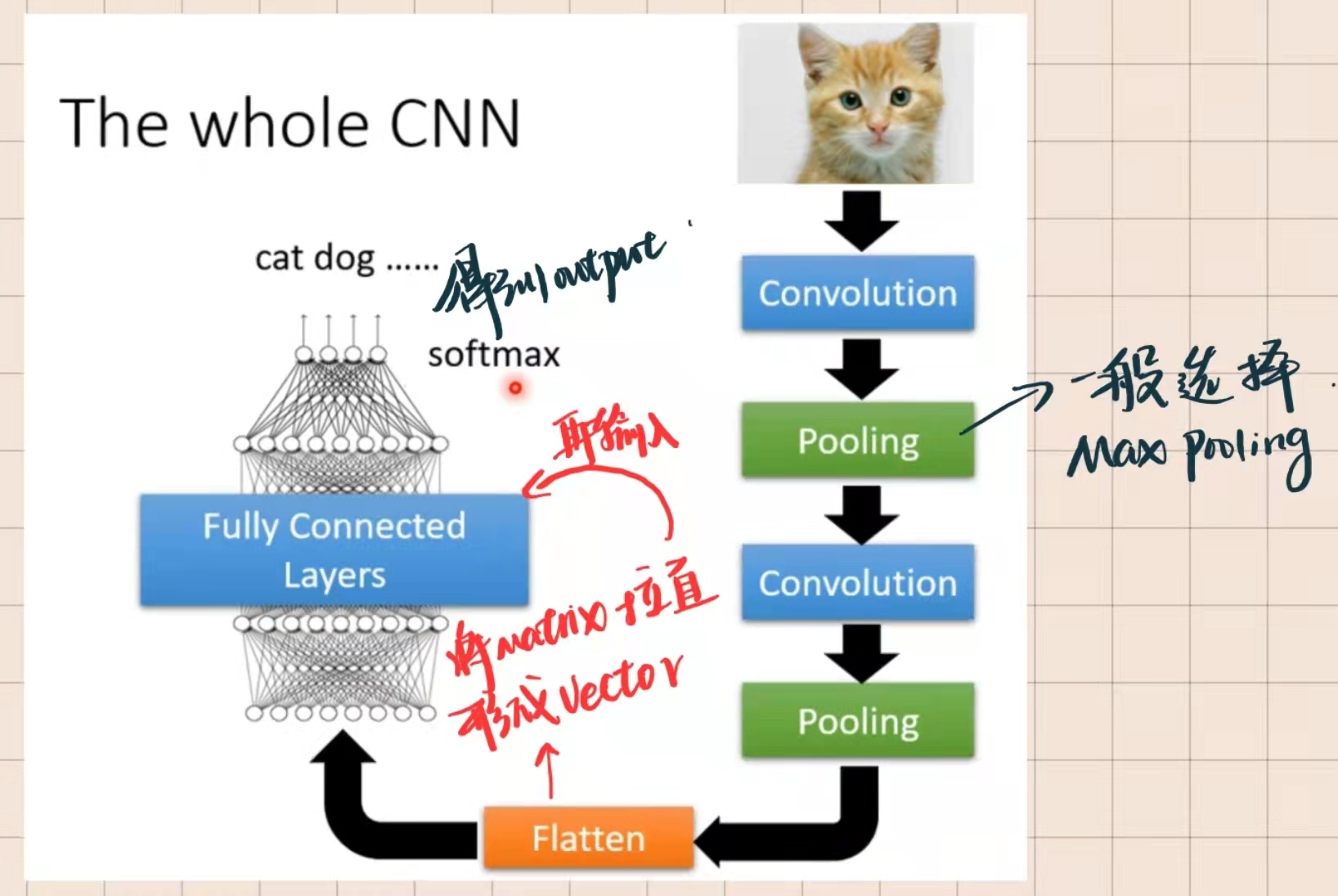
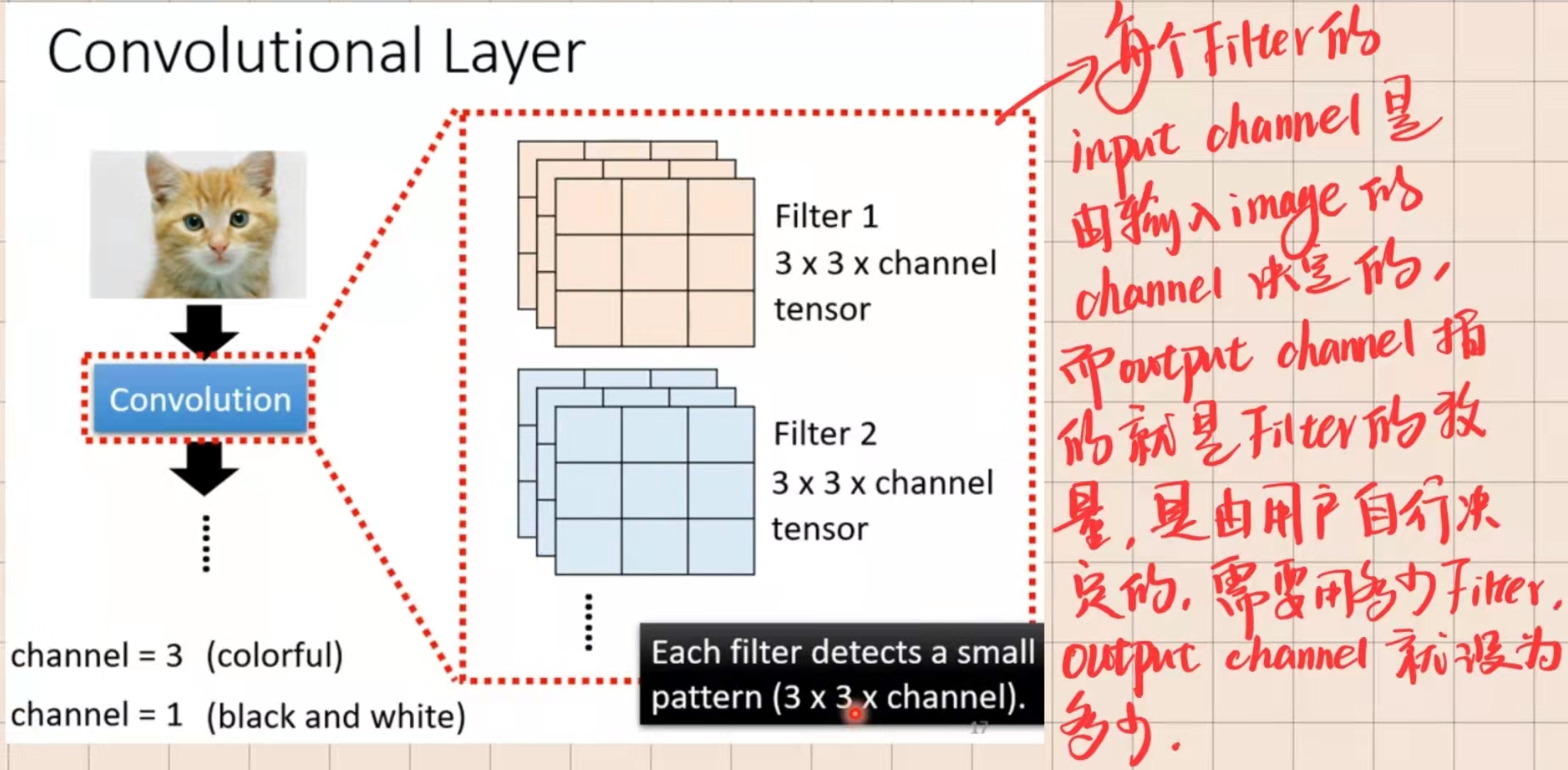
CNN基础架构如图所示
 padding的意义:为了使经过conv的图片大小不被压缩,设为‘same’即可
padding的意义:为了使经过conv的图片大小不被压缩,设为‘same’即可
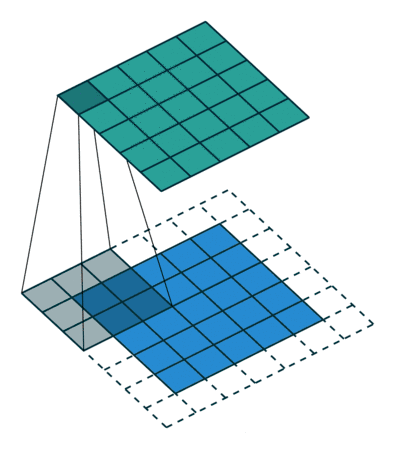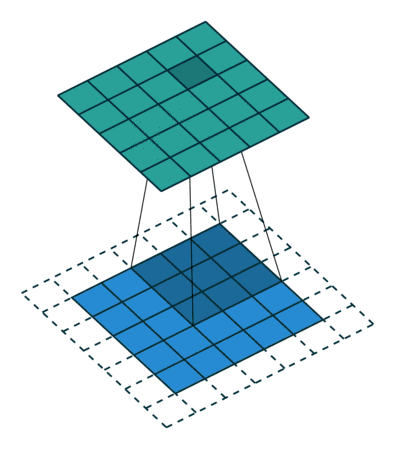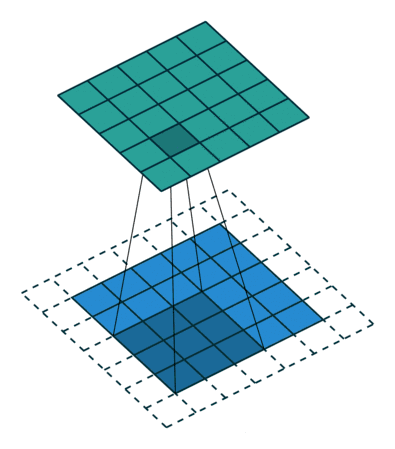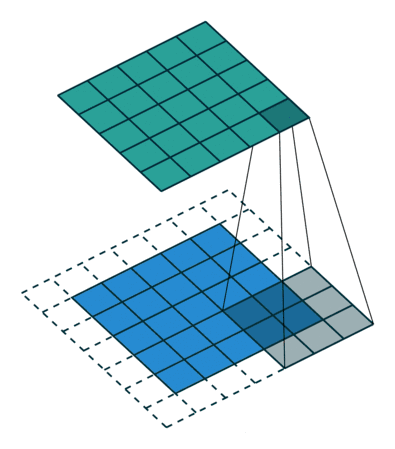 Pytorch实现如下
Pytorch实现如下
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height
out_channels=16, # filter个数
kernel_size=5, # filter size
stride=1, # filter movement/step,步长
padding='same', # 如果想要 con2d 出来的图片长宽没有变化, padding=(kernel_size-1)/2 当 stride=1
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # 在 2x2 空间里向下采样, output shape (16, 14, 14),由于经历了一个kerne_size为2的pooling,长宽变为之前的一半,经过16个filter,变为16
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 'same'), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # 再进行一次pooling,output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # 展平多维的卷积图成 (batch_size, 32 * 7 * 7)
output = self.out(x)
return output
cnn = CNN() # 初始化神经网络
训练过程
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # 分配 batch data, normalize x when iterate train_loader
output = cnn(b_x) # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
训练结束后预测十个数字看一下
test_output = cnn(test_x[:10])
pred_y = torch.max(test_output, 1)[1].data.numpy().squeeze()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')
结果一般都会很对,毕竟MINST也没什么难度
但是一台好的电脑真的很重要
©著作权归作者所有


